

How to prevent the coming inhuman future
How to prevent the coming inhuman future
On stopping the worst excesses of AI, genetic engineering, and brain-tampering


“Of present dues: the future comes apace
What shall defend the interim? and at length
How goes our reckoning?” —Flavius, Timon of Athens by William Shakespeare
There are a handful of obvious goals we should have for humanity’s longterm future, but the most ignored is simply making sure that humanity remains human.
It’s what the average person on the street would care about, for sure. And yet it is missed by many of those working on longtermism, who are often effective altruists or rationalists or futurists (or some other label nearby to these), and who instead usually focus on ensuring economic progress, avoiding existential risk, and accelerating technologies like biotechnology and artificial intelligence—ironically, the very technologies that may make us unrecognizably inhuman and bring about our reckoning. Indeed, just last week, major corporations introduced two new AIs: Google’s PaLM, an artificial general intelligence that performs better than the average human on a battery of cognitive tests, and OpenAI’s DALL-E, a digital artist, which jointly caused predictions for how fast AI development is going to proceed to accelerate significantly (at the prediction website Metaculus, predicted timelines jumped up by eight years). So the future will be upon us faster than we think, and we need to start making decisions about what sort of future we want now.
Longtermism gives a moral framework for doing this: it is the view that we should give future lives moral weight, perhaps at a discount, perhaps not; for whether one does or doesn’t discount hypothetical future people (vs. real people) turns out to be rather irrelevant. There are just so many more potential people than actual people, or even historical people who’ve ever lived. Only about ~100 billion humans have walked this Earth, and the number of potential people in the next 1,000 years of history alone might be in the trillions. Therefore, even if you massively discount them, it still turns out that the moral worth of everyone who might live outstrips the moral worth of everyone who currently living. I find this view, taken broadly, convincing.
But what counts as moral worth surely changes across times, and might be very different in the future. That’s why some longtermists seek to “future-proof” ethics. However, whether or not we should lend moral worth to the future is a function of whether or not we find it recognizable, that is, whether or not the future is human or inhuman. This stands as an axiomatic moral principle in its own right, irreducible to other goals of longtermism. It is axiomatic because as future civilizations depart significantly from baseline humans our abilities to make judgements about good or bad outcomes will become increasingly uncertain, until eventually our current ethical views become incommensurate. What is the murder of an individual to some futuristic brain-wide planetary mind? What is the murder of a digital consciousness that can make infinite copies of itself? Neither are anything at all, not even a sneeze—it is as absurd as applying our ethical notions to lions. Just like Wittgenstein’s example of a talking lion being an oxymoron (since a talking lion would be incomprehensible to us humans), it is oxymoronic to use our current human ethics to to answer ethical questions about inhuman societies. There’s simply nothing interesting we can say about them.

And humanness is an innately moral quality, above and beyond, say, happiness, or pleasure—it is why Brave New World is a dystopia, despite everyone being inordinately happy due to being pumped full of drugs, they are denied human relationships and human ways of living. It is why the suffering of a primate will always move us more than a suffering of a cephalopod, as proximity to our own way of living increases sympathy (and rightly so—e.g., octopuses are cannibals, and the mothers have to enter a pre-programmed biological death spiral right before their young are born so they don’t consume them in a grisly feast).
If you want to feel the moral worth of humanness most poignantly, visit Pompeii and see the plaster bodies holding hands, hugging, mothers sheltering their children in their last moments. There, amid the impossibly blue skies of the Mediterranean and the mountainous skyline ringing the shattered necropolis of a city, you will feel it. The humanness of the people of Pompeii is why we find their deaths so meaningful, so impactful, for they come to us just as the present with their humorous graffiti and the fragments of electoral candidate posters and their barstools and couches and gardens and gymnasiums and their tiled entryways that read CAVE CANEM (BEWARE OF DOG)—we can almost smell the garlic and hear the children laughing and the volcano rumbling. Walk Pompeii and you will find there is a thread between us and them, a thread that must not be severed.
{kind=link}
So, in some ways, keeping humanity human should be as central a pillar to longtermism as minimizing existential risk (the chance of Earth being wiped out in the future), both because of the innate moral value of humanity qua humanity and also because for inhuman futures we cannot make moral judgements regardless.
Although here I should admit that what counts as “human” is awfully subjective. For a (slightly) more objective definition, let’s turn to the greatest chronicler of the human: William Shakespeare.
When Carl Sagan chaired the NASA-assembled committee of artists and scientists deciding what music should go on the Golden Record of the Voyager spacecraft, one member apparently said that we should send “Bach, all of Bach!” to any future alien civilizations that discovered the record. Then, after a pause, the committee member said “Never mind, we’d be bragging.” That’s how one should feel about the work of Shakespeare; sending Shakespeare to aliens would be a brag about being human.
So we can lean on the Bard, and for any hypothetical future apply the “Shakespeare Test,” which asks:
Are there still aspects of Shakespeare’s work reflected in the future civilization? Conversely, is the future civilization still able to appreciate the works of Shakespeare?
For do any of us want to live in a world where Shakespeare is obsolete? Imagine what that means—that dynamics of people, of families, of parents and children, of relationships, of lovers and enemies, all these things, must have somehow become so incommensurate that the Bard has nothing to say about them anymore. That’s a horror. It is like leaving a baby in its crib at night and in the morning finding it metamorphosed into some indescribable mewling creature. There is still life, yes, but it’s incommensurate, and that’s a horror.
To see how to apply the Shakespeare test, let us consider four possible futures, each representative of a certain path that humanity might take in the big picture of history. While we’re at it, let each path have a figurehead. Then we can imagine the longterm future of humanity as a dirty fistfight between Friedrich Nietzsche, Alan Turing, Pierre Teilhard de Chardin, and William Shakespeare. Of the four, only Shakespeare’s strikes me as not obviously horrible.
William is on the back foot for now, but in a fight he’s scrappy, bald, and likely somewhat drunk. I wouldn’t bet against him.

“If every of your wishes had a womb, and fertile every wish, a million” —Soothsayer, Anthony & Cleopatra
The Nietzschean future
has its obvious attractions, while its dangers are more subtle. The future consists of what the name implies: Übermensch. If we imagine significant genetic editing becoming widespread, we may first simply imagine designer babies, little beings who seem quite unthreatening, just robust and happy creatures with perfect teeth and beautiful eyes. So let’s grow them up and imagine them as designer people, their rich parents having selected their genes specifically for athleticism, competitiveness, IQ, and leadership, with whatever polygenetic profiles those require. They’ll look a lot like the Greek gods. They’ll get into whatever college they want, they’ll never get sick, they’ll run faster, think deeper, and they’ll fuck harder. They will be gorgeous and whip-smart. But, just like the Greek gods, they will be a bunch of petulant, racist, sociopathic superpredators, great in bed but terrible in a relationship. For the sought-after designer traits will likely be things that only give direct selfish benefits, and knowledge of their genetic superiority will likely breed arrogance and contempt.
I’m certainly not the first to point this out; indeed, it’s a trope of science fiction, but let’s put some rigor on the bones of the argument. In the traditional kin selection view, whether a gene that promotes altruism is successful in a population is governed by the inequality rb > c. It’s a simple equation wherein r is the genetic relatedness of the other individuals the altruistic behavior targets, b is the benefit to those other individuals, and c is the cost to the original organism that expresses the altruistic behavior. However, there is also the possibility of group selection, in which groups of altruistic individuals, even if non-related, can outcompete groups of non-altruists. Therefore, some have argued the equation should more be more general: rb + Be > c. In this equation, the benefits have been split into two parts: the original rb, the basic benefit via kinship relations, and Be, the benefit to the group a whole above and beyond kinship benefits. As E. O. Wilson1 said:
"In a group, selfish individuals beat altruistic individuals. But, groups of altruistic individuals beat groups of selfish individuals."
In genetic editing the benefit to the group will be ignored, because no one wants to eat added extra cost c if you can design your own offspring. Of course, people won’t think of it that way, but every time they choose to maximize intelligence over empathy, or athleticism over bravery, or sex appeal over emotional warmth, this is what will be happening. It will be as if humans shed all the group-level selection they’ve undergone. This doesn’t mean we can’t use gene-editing to fix genetic diseases, but it does mean we should be incredibly cautious about other implementations. We’re messing with the source code of humans, after all.
For imagine being told you’ve been chosen, forged to be objectively better than other people. In the tiniest mechanisms of your cells. Now, look out at the world of normies. What is your level of respect for them? And if your answer isn’t a sneer, that you’re looking at a bunch of Neanderthals who should be replaced, that they are pitiable at best, you don’t understand the darker aspects of psychology. Shakespeare? Why should they care what he wrote? He’s just another Neanderthal.

“Why, I can smile, and murder whiles I smile; and cry 'Content' to that which grieves my heart; and wet my cheeks with artificial tears; and frame my face to all occasions.” —Richard III, Henry VI
Turing’s future
is also likely a horror, despite the genius and kindness of the man himself (it’s worth emphasizing that these futures are not the moral outcomes the thinkers would explicitly advocate for—rather, these are the unexpected or non-obvious downsides of futures dominated by the ideas of these thinkers).
And there’s a big downside in Turing’s future. The fly in the ointment is consciousness, which we still do not have a well-accepted scientific theory of. The big problem is that intelligence and consciousness seem, in our current state of knowledge, relatively orthogonal. This, if true, means that we are likely to have AIs that behave extremely intelligently (perhaps superintelligently) but are totally unconscious in their operations.
In 1980, the philosopher John Searle proposed a thought experiment capturing the intuition that there is an orthogonality between intelligence (or more broadly, behavior) and consciousness: a man sits in a room with many books, and meanwhile slips of paper are fed into the room filled with arcane symbols. His job is to look through the library and laboriously change the symbols according to the rules in the books, and then slip the paper back out. The reveal, of course, is that he’s conducting a conversation in Chinese, but does not know it. And there doesn’t seem to be a conscious mind that understands Chinese anywhere to be had in the thought experiment, a lack of what Searle calls “intentionality.”2 Chinese Rooms behave as if they understand, but, lacking conscious minds, they only appear to understand.
And it seems to me there is a fundamental disconnect regarding this thought experiment wherein many of those who discuss the longterm of humanity’s future (like a number futurists or members of the effective altruist and rationalist communities) think that the issues behind the Chinese Room thought experiment have been resolved. But meanwhile, most of us who work in academic fields exploring the nature of mind think that the Chinese Room thought experiment is broadly true—at minimum, it’s pointing to a real problem, and you really can have “Chinese Rooms” under certain conditions. This widespread agreement among professionals is captured by the 2020 PhilPapers Survey that examines philosophical positions across analytic philosophers at major universities (a tradition started by David Burgess and David Chalmers).
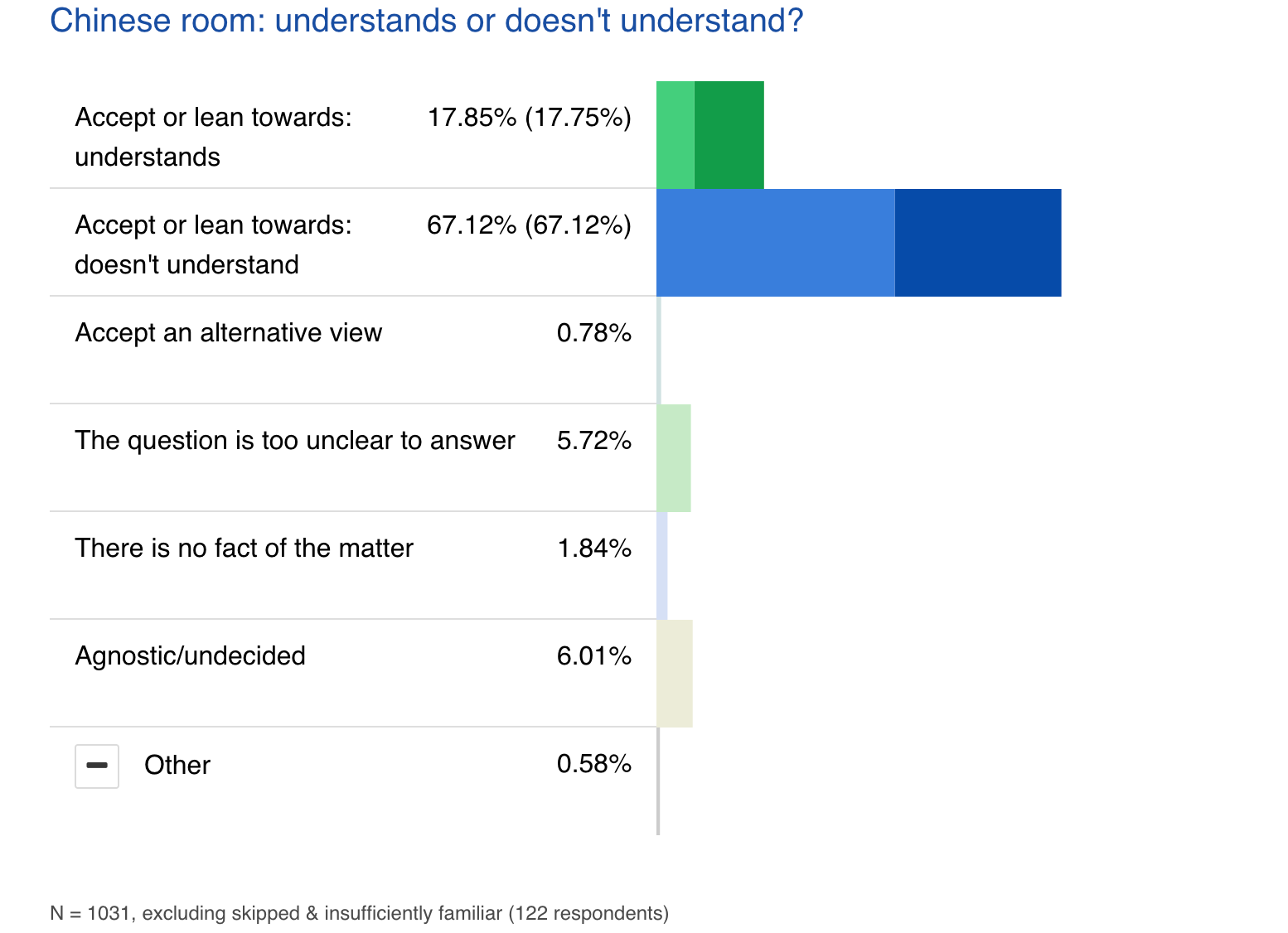
This is basically a slam-dunk in terms of agreement among professional philosophers, very close to easy questions like The Trolley Problem (73% responded you switch to save the 5 and kill the 1). Less than 18% of scholars think Chinese Rooms understand Chinese.
One reason for such high rates of professionals thinking Chinese Rooms are possible is that modern scientific research into consciousness has given some very clear actual examples of Chinese Rooms. Let’s take what is arguably the leading scientific theory of consciousness, Integrated Information Theory (IIT), which I worked with Giulio Tononi on developing aspects of while in graduate school. It is true that in IIT a brain simulated on a computer (what’s called a “brain emulation”), despite having the same input/output functional profile as a real brain, might not even be conscious at all, since it might not be integrating information in the right way that generates consciousness. The details are complex, but irrelevant—even if IIT isn’t true, it is inarguably one of the best scientific theories of consciousness that we currently have, and it clearly implies Chinese Rooms as a possibility. So it is a real worry.
In another example, AIXI is a recent well-understood and surprisingly simple algorithm for generating universal intelligence—on paper it’s the closest thing we have to something like AGI or superintelligence (ironically, however, AIXI is uncomputable). But the likelihood that AIXI’s operation is associated with any conscious intentionality is low—pretty much all the leading theories of consciousness wouldn’t attribute much, if any, consciousness to AIXI, since it’s just an expected value equation iterated over and over. Another example might be GPT-3, which often evinces its lack of understanding in specific contexts, but otherwise apes knowledge quite well.
Yet somehow this orthogonality is missed by leading longtermists, like William MacAskill, who consistently say with confidence things like:
The leading theories of philosophy of mind support the idea that consciousness is not essentially biological, and could be instantiated digitally (Lewis 1980; Chalmers 1996: ch. 9). And the dramatic progress in computing and AI over just the past 70 years should give us reason to think that if so, digital sentience could well be a reality in the future. It is also plausible that such beings would have at least comparable moral status to humans (Liao 2020), so that they count for the purposes of [longtermism].
In other words, according to MacAskill, it’s plausible that “digital beings” like brain uploads or AIs have at least comparable moral status to humans (implying they may even have more). Yet, this is not supported by current research into consciousness, where is it broadly agreed upon that Chinese Rooms are possible, perhaps likely, and therefore (depending on implementation) no matter how intelligent an AI appears it may not be conscious at all—there may be nothing it is like to be that AI, or even that uploaded brain—and therefore we actually owe such things no moral consideration. Not only that, we should view them as abominations, since they extinguish the light of consciousness and replace with with a cold reptilian nothingness, and anyone who cares about an ethical future should work directly to prevent their creation.
Again, the problem is the intelligence/consciousness orthogonality, that you can have one without the other. Right now the only view in which consciousness/intelligence orthogonality is not true is a view that turtles down by fully embracing the notion of system-level input/output functionalism—advocating that, as philosopher Dan Dennett might say, if it quacks like a duck, then it is a duck (if it behaves conscious, it is conscious).
Yet, system-level input/output functionalism (the idea that only the input/output of the system, or a system’s behavior, matters for consciousness) turns out to be a trivial and unfalsifiable theory. Indeed, myself and Johannes Kleiner recently proved this mathematically in a paper examining the falsifiability of scientific theories of consciousness, which you can read here. To give an extremely abridged English language version of our proof: input/output functionalism implicitly ascribes consciousness (or, if you like, “mental states”) to being equivalent to a system’s behavior, which in turn means that there is no possibility of any falsification of this theory, since under the theory behavior and consciousness can never be mismatched in any possible scientific experiment, and mismatches are required for falsification. So such a theory is always trivially true, and trivially true scientific theories are unfalsifiable. System-level input/output functionalism is not even wrong.
Results like this support the Searlean intuition that intelligence and consciousness are orthogonal—which means it’s likely you can have extremely smart non-conscious systems, i.e., Chinese Rooms.3 So in Turing’s future, your robot butler might be a Chinese Room, your AI assistant might be a Chinese Room, the AI governess that tutors your children, that oh-so-charming AI you voted for, the AI chatbot you fell in love with, the AI superintelligence turning your constituent atoms into a paperclip, all might be Chinese Rooms. A future of Chinese Rooms everywhere is a horror, as it is literally the extinction of the light of consciousness from the universe.
And does a Chinese Room care about Shakespeare? Even if for some reason they say they do, there’s no conscious experience; they appreciate Shakespeare as much as a wall spray-painted with “I LOVE SHAKESPEARE!” That is, not a whit.

If either of you know any inward impediment why you should not be conjoined, charge you, on your souls, to utter it. —Friar Francis, Much Ado About Nothing
Pierre Teilhard de Chardin:
born 1881, died 1955, jesuit priest, scientist, sometimes heretic, Darwinian, present at the discovery of the Peking Man, author of the beautiful book The Phenomenon of Man, and developer and promoter of the idea of a “noosphere.”
Teilhard de Chardin described his idea of a noosphere in a way we would now understand as an early form of the internet; it’s the first step in humans forming into a super-organism that is a global brain.
On the one hand we have a single brain, formed of nervous nuclei, and on the other a Brain of brains. It is true that between these two organic complexes a major difference exists. Whereas in the case of the individual brain thought emerges from a system of nonthinking nervous fibers, in the case of the collective brain each separate unit is in itself an autonomous center of reflection.
In Teilhard de Chardin’s vision of the longterm future, eventually that super-organism global brain expands throughout the galaxy, and then the universe, leading to a saturation of consciousness through all matter, which he called “the Omega Point” and related to Christian concepts.
As a young man I found Teilhard de Chardin’s views beautiful, but now I am older, perhaps slightly wiser, and truth be told it is also a horror.
First, the attraction is obvious. Who does not wish to share of another’s consciousnesses? It draws on our most primatological instincts—is it not when we experience such communal synchrony, like that of cheering in a crowd, or dancing, or in bed with our lovers, or playing with our children, that we are truly happiest?
But push it too far and it becomes a terror, considering what we know about consciousness scientifically. Back in the 1960s, Nobel-prize winner Roger Sperry and Michael Gazzaniga, the eventual godfather of cognitive neuroscience,4 investigated split-brain patients: people with epilepsy so bad the only treatment (at the time) was severing the corpus callosum, the bridge of nerves that connects the two hemispheres. Split-brain patients demonstrated a host of strange behavior that made it seem like they had two separate streams of consciousness, like how in careful experiments showing each hemisphere different visual inputs one hemisphere would make up random explanations for another hemisphere’s answers, or demonstrating alien hand syndrome wherein one hand (controlled by one hemisphere) actively worked against the goals of the other hand and its hemisphere, like unbuttoning a shirt the person was trying to put on.
All of which implies there is some unknown point where, if some hypothetical scientist damaged your corpus callosum enough, your stream-of-consciousness would split into two; similarly, in a split-brain patient, if we could somehow restore functionality slowly, there should be a point at which the two streams become one. And the same goes for, say, slowly hooking up your brain to another person’s brain. If we imagine hyper-advanced alien neuroscientists subjecting you to this experiment, increasing the bandwidth, likely there would be some sort of merger at some point.
Two streams becoming one sounds an awful lot like a group mind—and we should take the existence of group minds very seriously as a scientific possibility, since, after all, you are a group mind made up of individual neurons. And individual neurons don’t have their own consciousness; we should take away that if you’re a subset of a larger system that is conscious you might end up “enslaved” to it in an unconscious manner. There’s even some scientific evidence that the evolution of multicellularity led to a “complexity drain” on individual cells, where they outsourced much of their internal biochemical intelligence to the whole.
All to say, it might not be so glorious and awe-inspiring to watch an emergent godhead growing out of humanity like it’s busting out of a cicada shell. It might look more like the murder of billions, all our multifaceted experiences condensed down into a single stream of consciousness. And what is left behind? Husks and dust, and one of those discarded motes would be Shakespeare.
Elon Musk, despite obviously caring a great deal about the longterm future of humanity, seems determined to bring about de Chardin’s vision as soon as possible with his company Neurolink. His reasoning is that we need brain-to-machine (and brain-to-brain) interfaces to beat the AIs and keep humans relevant. But perhaps we should realize that the answer is not transforming ourselves ever more into linked machines just to beat AI economically. Perhaps we could, instead, collectively organize. Think of it like a union. A union for all humanity.

“We must away; Our wagon is prepared, and time revives us: All's well that ends well.”—Helen, All’s Well That Ends Well.
There can still be an exciting and dynamic future without taking any of these paths. And there’s still room for the many people interested in longtermism, and contributing to the future, to make serious, calculable, and realistic contributions to the welfare of that future. Humans might live on other planets, develop technology that seems magical by today’s standards, colonize the galaxy, explore novel political arrangements and ways of living, live to be healthy into our hundreds, and all this would not change the fundamental nature of humans in the manner the other paths would (consider that in A Midsummer Night’s Dream, many of the characters are immortal). Such future humans, even if radically different in their lives than us, even if considered “transhuman” by our standards (like having eliminated disease or death), could likely still find relevancy in Shakespeare.
But of course this fourth way, the way of Shakespeare, is also a horror. For it means, at the highest level of description, that the future is like the past. History doesn’t end, it just continues. It means there will be racism and nationalism in the future, it means there might be religious wars, it means there might be another holocaust, it means Stephen Dedalus never wakes up and keeps dreaming instead.
Personally, I’m on the side of Shakespeare. For it is not such a bad future, in the hands of humans. Humans after all, invented space travel and ended slavery and came up with antibiotics and snow plows and baby formula. We patch holes in clothing. We sing along to the radio in cars. We’re cute and complicated and fucked-up and kind. We kill, yes, but rarely, and we love far more. We’re not perfect. But we’re the best it’s going to get. Anything else will be unrecognizable and immoral, except by its own incommensurate and alien standards. So give me humans, fallible humans, poetic humans, funny humans, free humans, humans with their animal-like cunning, humans with their ten fingers and ten toes, human babies looking out the portholes of space stations just as they looked out over the hills of Pompeii, humans with their brains unfettered, humans colonizing the galaxy as individuals and nations and religions and collectives and communes and families, humans forever.
Humans forever! Humans forever! Humans forever!
This breakdown of the Hamilton equation also comes from E.O. Wilson. And while I know there is disagreement about whether group-level selection is “really real,” its ultimate ontological reality doesn’t particularly matter for the argument about the problem with gene editing; basically as long as group selection is an epistemologically viable description the argument stands (a fact pretty much everyone agrees upon).
There’s a philosophical debate to be had (and it has been had) about if mental intentionality is possible without consciousness. For simplicity’s sake I am assuming no and therefore substitute “conscious understanding” for “understanding” (but this assumption is not ultimately relevant to the main point).
Oftentimes those who dismiss Chinese Rooms will straw-man these kinds of pro-Searlean arguments as being a mere declaration that “all AIs are Chinese Rooms” by fiat, and therefore that this is “carbon chauvinism” or a failure to understand “multiple-realizability.” This misunderstands the argument significantly, since it is not that AIs are necessarily Chinese Rooms, but that they can be, perhaps likely will be.
Michael Gazzaniga and I have never met, but he did write a memoir where he mentioned a paper of mine, which he said he was particularly proud to be the editor of: the original introduction of the theory of causal emergence. I thought that was quite nice of him.
I dunno, dude. I think I disagree with your initial premise. I think Humanness is the first thing we need to get rid of, even if we accept as sacrosanct the fundamentally egotistical premise that Human survival should be some kind of prime imperative.
It’s thanks to Humanness that we’re wiping out 70,000-130,000 species every year. It’s thanks to hyperbolic discounting that today’s minor inconvenience is always more real to us than tomorrow’s global catastrophe. Family Values keep us churning out self-centred parasites, most of whom will just sit on the couch snarfing Cheetos and playing Animal Crossing until the ceiling crashes in, who we will defend with our lives for no better reason than that molecules have tricked us into making other molecules like them.
Of course, this isn’t just Human nature. Short-sighted selfishness is an inevitable hallmark of any organism forged by natural selection, because natural selection has no foresight. The difference in our case is the force-multiplier of Human intellect: that thing we could use to control our instincts, but instead use to make up complex rationalizations promoting them. The problem is that brains which evolved to handle short-term problems with local impacts now run technology with global impacts and long-term consequences. That’s Human.
We’re behaving completely naturally, of course. But it’s not working, is it? Being Human is killing us and our own life-support systems. Being Human threatens the survival of complex society itself.
We want to have a hope in hell of pulling this out of the fire, we gotta start behaving unnaturally ASAP.
There are indications of ways we might do that. Certain brain injuries that strip away Family Values, improving our ability to make ethical choices even if they don’t benefit our own larvae. Diseases that have the promising side-effect of suppressing the religious impulse. Hell, if we could just edit hyperbolic discounting out of the human mindset, get the gut to recognize the reality of future consequences, we’d be halfway home. Ironically, the best hope of saving Humanity might be by making us less Human. IMO this would be a good thing, both for our species and for all the others we’re wiping out—because this thing we are now, Erik, this thing you want to persist endlessly unchanged into the future: dude, it sucks.
Also I’m not entirely convinced that the incomprehension of the little guy in the Chinese Room really proves anything. Of course he doesn’t understand Chinese, any more than a single neuron would be able to tell you what the whole brain is thinking. Surely the question is whether the system as a whole comprehends, not whether any given gear or cog does.
I am not sure the Nietzschean future ends they way you predict. An interesting alternate reality, as portrayed in "Beggars In Spain", is that GM people recognize the humanness of the non-GM. Right now, people in Mensa don't say that low-IQ people are sub-human. (I presume, having never been to a Mensa meeting.)